[GNU Manual] [No POSIX requirement] [Linux man] [No FreeBSD requirement]
Summary
shuf - shuffling text
Lines of code: 611
Principal syscall: write()
Support syscalls: open(), close(), fadvise()
Options: 15 (6 short, 9 long, does not include perm digits)
Added to Coreutils in August 2006 [First version]
Number of revisions: 60 [Code Evolution]
input_from_argv()- Loads user-provided arguments in to an arrayinput_size()- Returns the size of the input if possiblenext_line()- Returns a pointer to the next lineread_input()- Reads lines from input for standard permutation. Allocates heap, and returns sizeread_input_reservoir_sampling()- Reads lines from input used in reservoir samplingwrite_permuted_output_reservoir()- Outputs permuted lines from the reservoirwrite_permuted_lines()- Outputs lines using a permuted indexwrite_permuted_numbers()- Outputs a permuted number rangewrite_random_lines()- Outputs a random line with replacement using an entropy sourcewrite_random_numbers()- Outputs a random ranged number with replacement using an entropy source
die()- Exit with mandatory non-zero error and message to stderrerror()- Outputs error message to standard error with possible process terminationrandint_all_new()- Creates a new random source structure (in randint.c)randperm_new()- Generates a new permutation index array (in randperm.c)
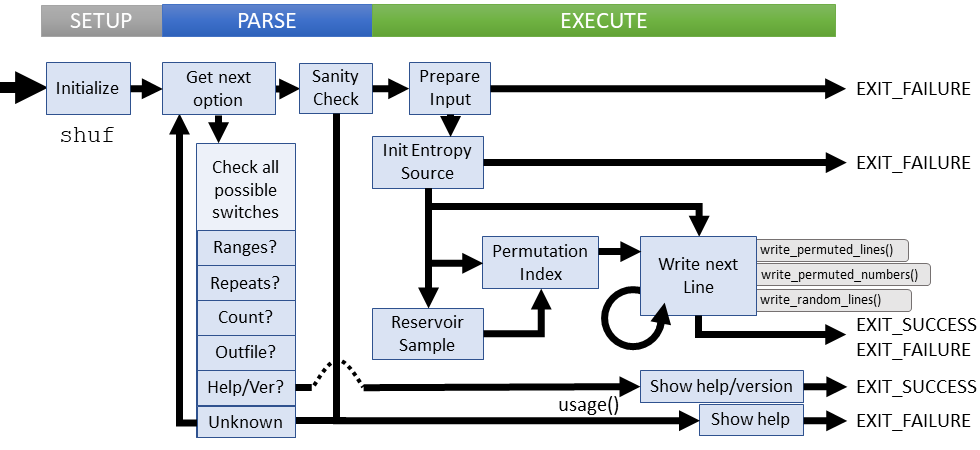
Setup
shuf manages execution by declaring a long list of local variables in main():
echo- Flag if each command line argument is considered a lineeolbyte- The line delimiter character. Usually \n, but may be \0.head_lines- The number of output lines requested by the userhi_input- User specified high input numberi- integer to hold the number of successful byte written**input_lines- Pointer to the list of linesinput_range- Flag if the user specified an input range**line- Pointer to the permuted line arraylo_input- User specified low input numbern_lines- The number of lines to outputn_operands- The number of user-provided arguments on the CLI**operand- Pointer to the beginning of the user provided argumentsoptc- The character for the next option to process*outfile- The name of the output file*permutation- Pointer to the permutation index array*randint_source- The generated random source structure (specific randread source)*random_source- Name of the entropy source filerepeat- Flag to triggle sample with replacement*reservoir- The linebuffer used for reservoir samplinguse_reservoir_sampling- Flag if reservoir sampling is used
Parsing
Parsing answers the following questions to define the execution parameters
- What is the source of input? File, Arguments, Ranges?
- Do we repeat lines (sample with replacement)?
- Do we output all input lines, or a subset?
- How is output delimited?
Parsing failures
These failure cases are explicitly checked:
- Using both input ranges and arguments for input
- Adding extra arguments when reading input ranges
- Nonsensical input ranges or output line counts
- Providing multiple input ranges
- Specifying multiple input or output files
- Unknown option used
User specified parsing failures result in a short error message followed by the usage instructions. Access related parsing errors die with an error message.
Execution
Input comes from three possible sources: Read in from a file, provided as arguments on STDIN, or generated via input range options. The source determines the execution path for the output. After input source is chosen, execution looks like this:
- Initialize random (default: ISAAC cipher - nonce from
/dev/urandom) - Prepare the resevoir sample, if necessary
- Build a permutation index, if necessary
- Open the output file, if requested
- Write output lines/numbers either randomly or permuted
- Repeated last write until all lines written
Failure cases:
- No lines written
- Unable to open input source or output file
- Unable to initialize random source
- Unable to read from input source
- Input is too large to read in
All failures at this stage output an error message to STDERR and return without displaying usage help
Extra comments
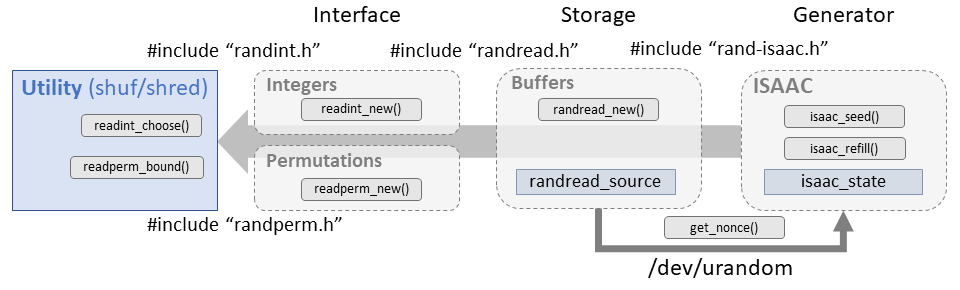
Source of random
Coreutils includes a self-contained implementation of the ISAAC cipher used in both the shuf and shred utilities. There's a fair amount of plumbing between the entropy source and the utility needed to generate, store, and distribute the numbers. This allows a minimal framework to bring random numbers in to this (and future) utilities. Consider the following diagram:
Reservoir Sampling
shuf employs reservoir sampling (paper) to quickly reorder a large, unknown-sized input. The key idea is to read all lines sequentially in to the reservoir until it's full, then randomly swap subsequent lines in to the reservoir with decreasing probability. The result is a random selection of lines built in one pass without knowledge of where the end of input lies. The process happens entirely in read_input_reservoir_sampling() and flows like this:
- Fill the reservoir with input lines (sequential)
- Realloc reservoir as needed to continue growth
- Read in a new input line beyond the max reservoir size
- Select a line to replace (uniform random).
- If selection falls within the reservoir, swap it out
- Otherwise, line discard newly read line
- Repeat until size limit or end of input
- Return count of lines processed
Reservoir construction alone does not guarantee shuffled output. Consider the case where the input size matches the reservoir size -- the reservoir contains exactly the input in order. While we can mitigate this by enforcing a large minimum input size, there is likely still read-order bias for small inputs. The solution is to sample the reservoir from using our PRNG as an index. (See above). In short, construct the reservoir, then randomly read from the reservoir to produce shuffled results.