[GNU Manual] [No POSIX requirement] [Linux man] [FreeBSD man]
Summary
ptx - produce permuted indexes
Lines of code: 2154
Principal syscalls: fopen(), fread() (both via read_file())
Support syscall: fstat() (also via read_file())
Options: 35 (17 short, 18 long)
Descended from ptx in Version 2 UNIX (1972)
Added to Textutils in August 1998 [First version]
Number of revisions: 114
The ptx utility realized an early computing goal to automate a labor intensive task: creating permuted indexes from a text source. The original use-case was to build the index for the physical UNIX manuals based on the man pages.
Helpers:compare_occurs()- Compares OCCURS to return which goes firstcompare_words()- Compares WORD locationscompile_regex()- Compiles a regular expressioncopy_unescaped_string()- Processes a string and evaluates escapesdefine_all_fields()- Computes position and length of fields in OCCURSdigest_break_file()- Processes the file of break charactersdigest_word_file()- Processes the file of words to ignorefind_occurs_in_text()- Creates OCCURS structures for each input WORDfix_output_parameters()- Sets the output parameters according to user specifications from cligenerate_all_output()- Prints data lines from theoccurs_table[]initialize_regex()- Initializes pattern match tablesmatching_error()- Fails out of regular expression matchingoutput_one_dumb_line()- Outputs a line as-is with trailing newline charoutput_one_roff_line()- Outputs a line in [n|t]roff format (leading typesets)output_one_tex_line()- Outputs a line is TeX notation: \typeset {...}print_field()- prints a BLOCK of textprint_spaces()- Prints a given number of spacessearch_table()- Binary search for a WORD in a WORD_TABLEsort_found_occurs()- Sorts the globaloccurs_table[]swallow_file_in_memory()- Loads a file in to contiguous memory and collect statistics
re_compile_pattern()- Compiles a regular expression to a pattern buffer
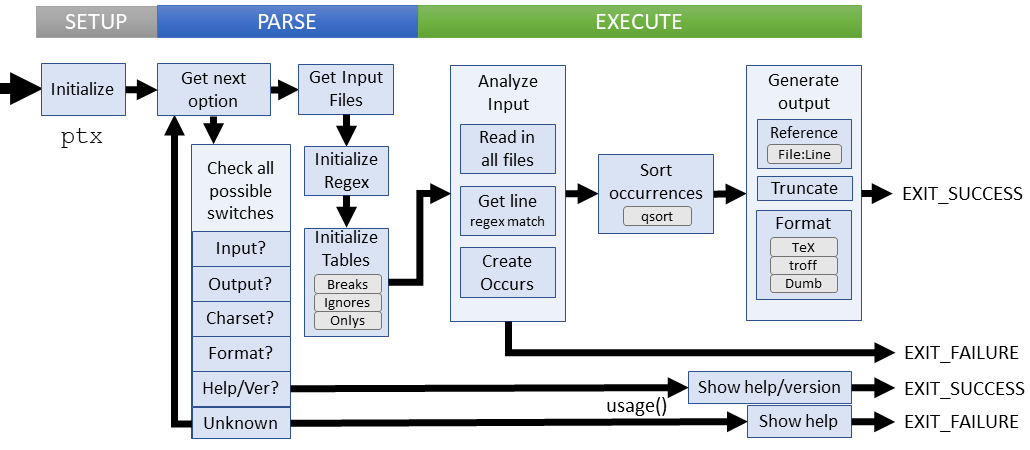
Setup
Several global structures, flags, and other variables are needed for collecting and organizing input text. These include:
Structs:
struct BLOCK- An arbitrary space in memory (*start, *end)struct regex_data- An expression and a compiled patternstruct OCCURS- The context of a keywordstruct WORD- A single word as a start pointer and sizestruct WORD_TABLE- An array of words, including a start, total size, and used size
OCCURS structures are managed through a global table pointer, *occurs_table[]
WORD_TABLEs have two global references in the ignore_table and only_table
Flags:
auto_reference- Flag to track file:line outputgnu_extensions- Flag to enable extended GNU featuresignore_case- Flag to distinguish between upper/lower case during sortinginput_reference- Flag to process leading line text for contextright_reference- Flag to force reference text to the end of a line
main() initializes a few variables used througout the utility:
optchar- The next argument for processingfile_index- Index toinput_file_name[]for multiple input files
Parsing
Parsing for ptx has a few more steps than most utility because some execution parameters need to be pulled from other files. Like other utilities, we begin by reading the line options to answer questions:
- What are the input sources?
- What is the desired output format?
- Are there external parameters in other files (ignore/only lists, etc)
- Any special character set considerations, such as case handling?
Parsing failures
These failure cases are explicitly checked:
- Invalid gap widths or line widths
- Extra arguments
- Unable to open any parameter files
- Using unknown options
Execution
ptx executes in three stages: analyzing data, sorting data, and outputting data.
Analyzing Data
The goal populate the global occurrence table after reading all input data. Along the way, we apply the inclusion/exclusion filters and regex patterns to focus on relevant data. For each file:
- Read the file in to memory (
swallow_file_in_memory()) - Check each line against the gives regular expressions
- Check each word and its context
- Verify that the word isn't ignored or is explicitly required
- Build an occurence entry in the global table
Sort Data
qsort() the occurrence table using the provided compare_occurs() comparator. The basis is the lexographic ordering of keywords for each occurrence.
Output Data
The output phase is dictated by the three supported formats: 'dumb' terminal, TeX, and troff. Before the output is processed, several parameters are defined for all formats:
file_index- The input file indexline_ordinal- The line count remaining for the filereference_width- Holds the length of the reference stringcharacter- A character value*cursor- Pointer within a string
Many of the globals already mentioned are computed at this stage in preparation for output generation.
Generating output means iterating over the sorted occurs_table[]. For each entry:
- Compute the position and length of each field: Reference, tail, before, keyafter, head.
- Output the appropriate formats
- Dumb terminal - A single line with all fields in order
- TeX - line begins with '\\' and fields enclosed in curly braces
- troff - line begins with '.' and fields are quoted
Execution failure cases concern regular expressions:
- A regular expression match or compile fails
- A zero-length regular expression match