[GNU Manual] [POSIX requirement] [Linux man] [FreeBSD man]
Summary
head - output the first part of files
Lines of code: 1096
Principal syscall: fwrite()
Support syscalls: open(), fstat()
Options: 14 (5 short, 9 long, not including number options)
Descended from head included in System V (1985)
Added to Textutils in November 1992 [First version]
Number of revisions: 166
copy_fd()- Copies data from file to buffer then writes to STDOUTdiagnose_copy_fd_failures()- outputs the appropriate message for an error codeelide_tail_bytes_file()- Omit lines from the end, counting by byteselide_tail_bytes_pipe()- Buffers bytes from fd and omits as specifiedelide_tail_lines_file()- Omit lines from the end, counting by lineselide_tail_lines_pipe()- Buffers lines from fd and omits as specifiedelide_tail_lines_seekable()- Seek and omit as neededelseek()- Moves position within a file and checks errorshead()- Primary processing function for an input filehead_bytes()- Output from the beginning, counting by lineshead_file()- Opens a file for processing byhead()head_lines()- Output from the beginning, counting by bytesstring_to_integer()- Convert string to int (Wrapper for __xdectoint()write_header()- Adds a header to the output if neededxwrite_stdout()- Writes data from buffer and checks for errors
die()- Exit with mandatory non-zero error and message to stderrerror()- Outputs error message to standard error with possible process terminationxset_binary_mode()- Set the file descriptor access mode
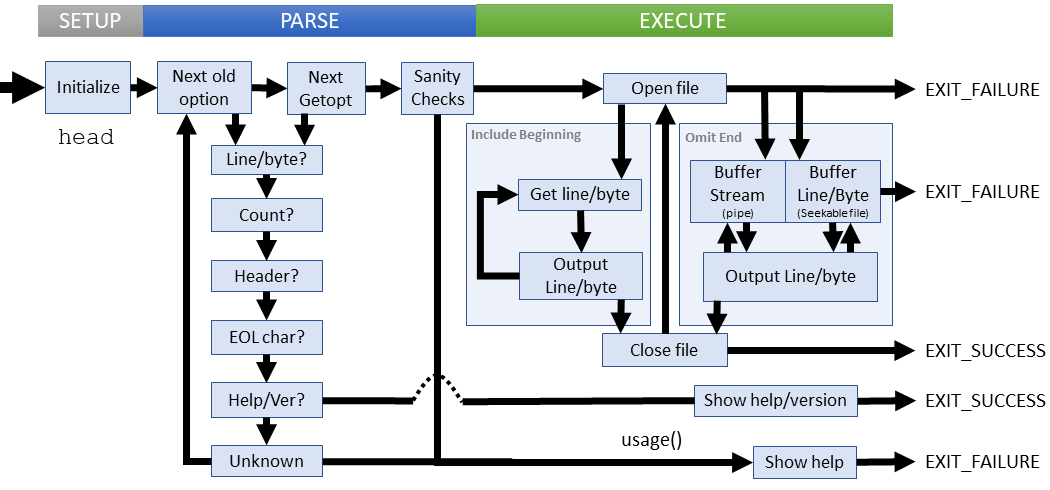
Setup
Several variables are defined at global scope, including:
presume_input_pipeis a flag for processing pipes (skip file check)- The
print_headersflag allows headers to be printed - The
line_endcharacter holds the line delimiter
main() initializes the following:
header_mode- Defines when to print he adersok- Holds the return status of the utilityc- The character value of the next optioni- Generic iterator index for file arrayn_units- The number of lines/bytes to processcount_lines- Flag for line or byte modeelide_from_end- Flag for include or exclude modedefault_file_list[]- The input files to process if none are provide (STDIN)file_list- The user provided viles to process
Parsing
Parsing begins differently than most utilities. We start by looking explicity for legacy syntax which begins with a line/byte count and options appended (i.e head -6v if we want to see the first 6 lines without a header). This routine ends by resetting the option/argument pointers
Now we parse the options again with getopt to the same effect for the new syntax
We should know the following:
- Are we processing lines or bytes?
- Are the lines/byte inclusive from the beginning or exclusive from the end
- Do we output headers?
- Do we collapse consecutive spaces?
Parsing failures
Two failure cases:
- Unknown or invalid options
- Invalid number of bytes to process
Execution
Implementing head would be self-explanatory if it weren't for the omit case on sequential stream (pipes). Let's consider the basic cases and expand the problem
Output from the beginning of a file
Set the counter for the number of lines/bytes we need to output. Then read one 'unit' of input, decrement the counter, output the data and repeat until the counter is 0. That's it!
Output until a given point before the end of a file
This situation is more subtle. We don't necessarily know where the point is from the beginning of a file, but since the data stream is persistant, we have random access. We can start at the end of the file and move backward with the counter to find the point to exclude. Then output from the beginning up to the point. A little more work, but not as problematic as the file case.
Output until a given point before the end of a sequential stream
We can only read the data sequentually from beginning to end, and we can only read it once. We don't know how large the input is thus we cannot tell how far from the end any byte of data might be. We must buffer the data.
Read the input in to a buffer that's as least as large as the part of the input we want to exclude. When the buffer fills, then we know that each subsequent input read should pair with an output write. This is the general solution to an arbitrarily large input of unknown size. The actual coreutils implementation follows this strategy as well as a (possibly) better-performaning solution involving double-buffered windows.
Failure cases:
- Unable to
fstat()input file - Unable to seek an input file
- Failure to read an input file
- Unexpected end of file
- Failure to write to output
- Trying to process and unreasonably large file
- Unable to open/close input
All failures at this stage output an error message to STDERR and return without displaying usage help