[GNU Manual] [POSIX requirement] [Linux man] [FreeBSD man]
Summary
csplit - split a file into context-determined pieces
Lines of code: 1527
Principal syscall: write()
Support syscalls: open(), close()
Options: 17 (7 short, 10 long)
Descended from csplit as implemented in System III (1982) (appeared internally as early as 1980)
Added to Fileutils in November 1992 [First version]
Number of revisions: 212
The csplit utility is conceptually simple, but includes many boilerplate functions for reading and buffering input
check_for_offset()- Checks a offset for the regular expressioncheck_format_conv_type()- Verifies format flagscleanup()- Regular cleanup after execution (closes output, restores signals)cleanup_fatal()- Cleanup after a fatal error and exits failureclear_line_control()- Initializes a lineclose_output_file()- Closes an output file and prints the number of bytes writtencreate_new_buffer()- Allocates a new buffercreate_output_file()- Creates a new output file streamdelete_all_files()- Deletes all the files that have been createddump_rest_of_file()- Outputs each input line to the current output streamextract_regexp()- Finds and verifies regular expressionfind_line()- Finds a specific line in a bufferfree_buffer()- Deallocates a memory bufferget_first_line_in_buffer()- Finds the first unread buffered lineget_format_flags()- Counts the printf format flagsget_new_buffer()- Returns a new buffer, either created or reusedhandle_line_error()- Handles EOF cases while reading filesinterrupt_handler()- Custom interrupt handler to delete fileskeep_new_line()- Buffers a new linemax_out()- Calculates the maximum size of a format (in bytes)new_line_control()- Create and initialize a lineno_more_lines()- Confirms that no more lines are available (bad comment in source?)load_buffer()- Fills a buffer with inputmake_filename()- Generates a new file name stringnew_control_record()- Allocates a new control structparse_patterns()- Processes user provided patternsparse_repeat_count()- Handles repeating command line inputprocess_line_count()- The split procedure using line numberprocess_regexp()- The split procedure using regular expression matchesread_input()- Reads a chosen number of bytes from inputrecord_line_starts()- Scans a buffer for the number of linesregexp_error()- Handles regular expression errorsremove_line()- Finds the first unread line in a buffersave_buffer()- Add the given buffer to the list of bufferssave_line_to_file()- Outputs a single line to the current output streamsave_to_hold_area()- Saves a partial line to a bufferset_input_file()- Opens the given filesplit_file()- The primary split procedure for the input filewrite_to_file()- Writes all buffered lines to the current ouput streamxalloc_die()- Error handler for out of memory
die()- Exit with mandatory non-zero error and message to stderrerror()- Outputs error message to standard error with possible process termination
Setup
The csplit utility defines a few global structures to manage input data. These include:
struct buffer_record- A buffer for holding lines and linking to the next bufferstruct control- A compiled regular expression for matchingstruct cstring- String information (start pointer and length)struct line- Buffered line information
csplit uses several global flags and variables, including:
bytes_written- The number of bytes written for the current output filecaught_signals- The caught signal setcontrol_used- The number of controls (regex patterns)*controls- The pointer to the first controlcurrent_line- The index of the current linedigits- The number of digits used in the output file nameelide_empty_files- Flag if empty files should be removed*filename_space- The buffer for output file names (fits largest possible)files_created- The number of output files created**global_argv- The list of argv componentshave_read_eof- Flag if we've seen EOF*head- The beginning of the list of buffer*hold_area- Pointer to the current partially read linehold_count- The number of bytes in the current partially read linelast_line_number- The last line number in the buffer*output_stream- The current output file stream*output_filename- The current output file name*prefix- The output file name prefix stringremove_files- Flag if files should be removed on error*suffix- The output file name suffix stringsuppress_count- Flag if we do not output the file size in bytessuppress_matched- Flag if we have a suppression pattern
main() adds a few more locals before starting parsing:
prefix_len- The length of the output file name prefixoptc- the next option character to processmax_digit_string_len- The maximum possible size of a file name (includes suffix and name)
Parsing
Parsing breaks down the user-provided options to answer these questions about handling input data:
- Should we process all input, or only early lines or digits?
- Do the output file names need a prefix or suffix?
- Should files with errors be removed?
- Should size counts be printed for output files?
Parsing failures
These failure cases are explicitly checked:
- User provides an invalid count number
- Not enough operands (need at least an input file and a matching pattern)
- Unknown option used
User specified parsing failures result in a short error message followed by the usage instructions. Access related parsing errors die with an error message.
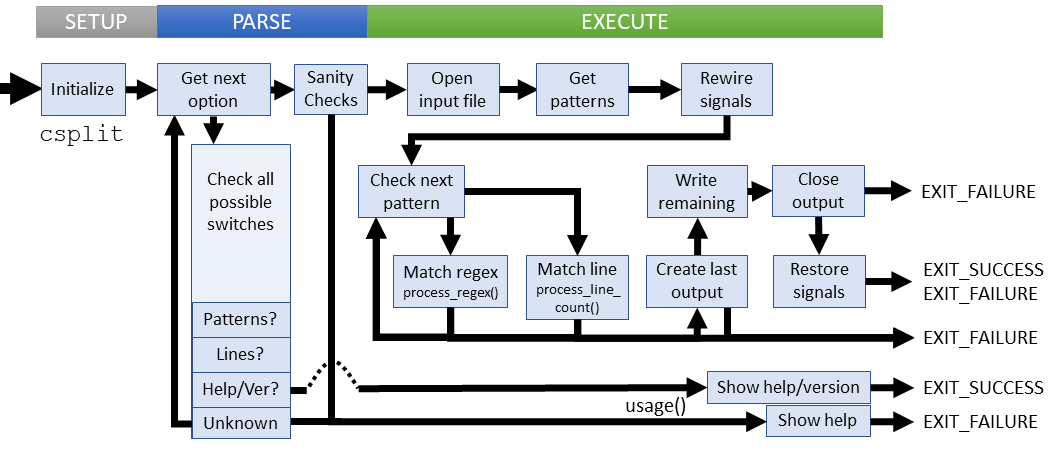
Execution
csplit is one of several utilities that defines a custom signal handler. In this case, it is used to delete any files that were created that the utility must delete if interrupted. The change occures between setting up the input stream and just before the split operation beings.
The utility has two primary 'working' functions, process_regexp() and process_line_count(), which extract the file sections based on regular expression matches or line number respectively.
The overall process for csplit looks like this:
- Measure the output file names (length)
- Check and set the input file name
- Gather the section patterns, which may be regex or line numbers
- Add a custom signal handler to the usual interrupting signals to delete any created files (and call into the default handler)
- Check the next pattern and pass to the appropriate processor (regex or line)
- Create the output file for that pattern.
- Process all matches (write to output file)
- Discard the remaining input
- Close the output file
- Move to the next pattern and repeat and the matching sequence
- Create a generic output file for unmatched input
- Write unmatched input to the final file
- Close final file
- Restore default signal handlers
Failure cases:
- Inconsistent patterns provided by the user
- Unable to open or close I/O files
- Unable to read from input source
All failures at this stage output an error message to STDERR and return without displaying usage help